Dollars for Docs
This is my most well-known investigative news project, thanks to the hundreds of news and medical organizations that used our data to produce their own reports, and of course, all the regular people curious about their own doctors. The popularity of Dollars for Docs spurred numerous changes in the industry, including Eli Lily creating an independent screening process for its hired speakers and medical schools revising their conflict-of-interest policies.
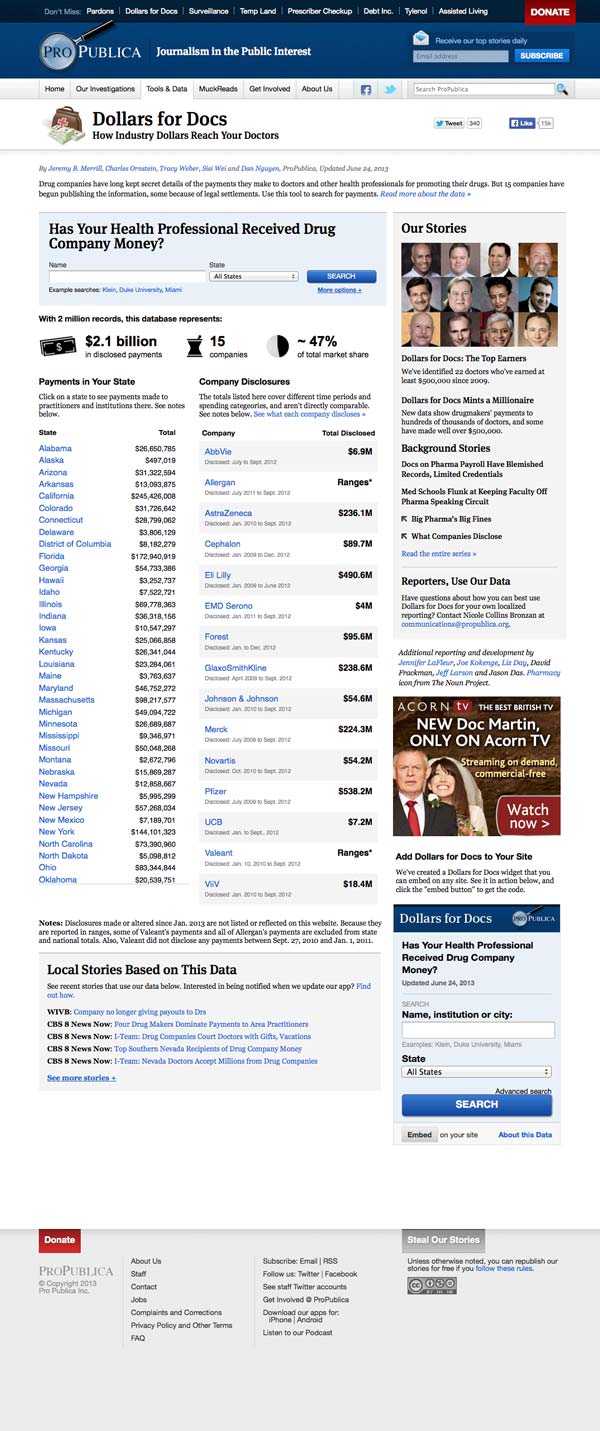
One of the most satisfying aspects of D4D was how it started in my living room. I was writing a blog post about the practical benefits of programming for journalists, when I came across a New York Times article about how Pfizer, which was forced to disclose its payments to doctors, had published their data in an inconveniently designed website. The site was servicable, but its structure made it difficult to do even the most rudimentary analysis.
So I scraped Pfizer’s listings and published the data and the code on my blog. Later that week, my colleague Charles Ornstein asked me if it were possible to collect data for all the drug companies, and this is how ProPublica’s biggest data project started.
Even with my colleagues Ornstein’s and Tracy Weber’s reporting expertise, I did not think the project would have a real impact. The political momentum to impose transparency on the companies was already in place, due to reporting by The Times and medical researchers in 2007. However, I vastly underestimated the impact of making the data easy-to-find. Even if ProPublica was only revisiting the issue, I saw that a well-designed application could bring new angles to the story, through sheer magnitude and breadth of information.
People almost always overestimate the technical sophistication behind Dollars for Docs, especially since I wasn’t a great programmer back then. While it was time-consuming to collect the data and build the website, the hardest parts were the most pedantic. Such as: how to efficiently and, most importantly, accurately fetch the data and pipe it to reporters, some of whom didn’t know how to use spreadsheets. The biggest surprise for me of Dollars for Docs was how great and basic the need was for reporters (and doctors) to better understand the nature of data. Not just how to process it in a technical way, but to fundamentally recognize its values (and limitations).
While researching the project, I spoke with Dr. Joseph Ross, who was the first to report on the state and implications of this data in 2007. Dr. Ross told me that in Minnesota, this data had been public record but unexamined for nearly a decade, until he and his associates photocopied and hand-entered the records into Access. By the time I started my project, the data was by comparison trivially easy to gather and analyze. That I was able to make a big project out of it taught me to never assume that when something is public, that it also has been looked at.
I ended up writing a series of in-depth technical guides explaining how I wrangled the data together: