SOPA Opera
SOPA Opera is not one of my most important projects, but it is one of my sentimental favorites. Like Dollars for Docs, it was something I started from home. The debate over the Stop Online Piracy Act had been growing, but I was annoyed that doing a Google search for a politician’s name and “position on SOPA” usually turned up nothing.

This “there should be a list!” impulse has been at the heart of ProPublica’s best news applications. The Bailout Tracker, my very first news app, originated from my colleague Paul Kiel writing down names of banks that had individually been announcing their bailouts. So SOPA Opera was just a list of Congressmembers and what they think about SOPA. Of course, it’s obvious why this kind of site doesn’t exist already: politicians don’t need or desire to take a hard position on minor issues before a vote, and SOPA was most certainly a niche issue.
There are enough great open government APIs that make it easy to build a database of U.S. Congress activity. The most time-consuming part was researching each Congressmember’s statements and reading through old news stories. I hadn’t yet taught myself machine learning. But this kind of research, which requires a few judgment calls, cannot be easily automated. However, I made the process as efficient as possible by setting up a Google Spreadsheet that I could fill in casually.
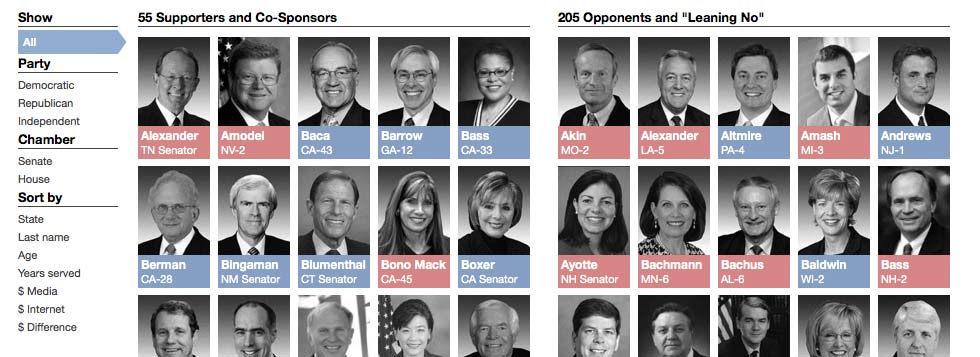
After a week, I had gathered enough data to build the app. The front page showed a visual tally of my research, but I designed the site to have endpoints that made it particularly shareable. Down to the state level, you could see a tally of who said what. And each Congressmember had a page, with the compiled research I had done (including votes and positions on past related bills) and conveniently accessible contact information.
I published SOPA Opera on my own server and let it spread through word of mouth. Activists linked to the state pages, telling friends to write their local legislators and demand answers. I soon ended up solving my own problem: whenever you Googled a Congressmember’s name and SOPA, you’d end up at my site. In the first week it came out, it had over 100,000 visitors and a congressional staff member had emailed me to let me know his boss opposed SOPA.
I moved SOPA Opera onto ProPublica’s servers and it grew from there. Because I had designed it to operate from a Google Spreadsheet, I could efficiently update it as users told me what they heard from their legislators. On the day of the Internet blackout, SOPA Opera had over one million page views, a single-day record, thanks to links from Reddit and Craigslist.
The most interesting lesson I learned was, yet again, the fundamental nature of our ability to just know things. The best feature of my site was that it put all the data – the positions of each Congressmember on SOPA – on one page. That simple compilation brought out revelations that should not have been “revelations”. A common complaint I got was that there was no way that Sen. Al Franken would ever support SOPA. The tech crowd, in particular, believed that only Republicans could favor such a bill, and one reader even wrote me repeatedly to accuse me of slandering Sen. Franken, even though Franken is listed in the official records as a co-sponsor of the SOPA’s Senate version. To me, it was always obvious this was not a Republican vs. Democratic issue, but for activists who were passionate about the topic, they had to see it on SOPA Opera to believe it.
So SOPA Opera wasn’t an important project, but it was a good exercise, and I’ve since been very interested in other ways to make the issues and debates of our democracy more comprehensible and organized.